RESNET神经网络
背景
网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果。验发现深度网络出现了退化问题(Degradation problem):网络深度增加时,网络准确度出现饱和,甚至出现下降。
He 在论文中举了一个例子,假设一个比较浅的网络已经可以达到不错的效果,那么即使之后堆上去的网络什么也不做,模型的效果也不会变差。而之前的深度网络出现退化问题,所以很明显什么都不做恰好是当前神经网络最难做到的东西之一。
MobileNet V2 的论文也提到过类似的现象,由于非线性激活函数 ReLU 的存在,每次输入到输出的过程都几乎是不可逆的(信息损失)。我们很难从输出反推回完整的输入。因此 MobileNet V2 论文中选择去掉低维的 ReLU 以保留特征信息。
我们可以认为,为了实现非线性,激活函数让特征在传播过程中丢失了信息,因此这类的神经网络都无法做到“恒等映射”。
因此,可以认为 Residual Learning 的初衷,其实是让模型的内部结构至少有恒等映射的能力。以保证在堆叠网络的过程中,网络至少不会因为继续堆叠而产生退化!
残差学习
前面分析得出,如果深层网络后面的层都是是恒等映射,那么模型就可以转化为一个浅层网络。那现在的问题就是如何得到恒等映射了。但是要让一个神经网络拟合其实是非常困难的。于是 He 等人换了一个思路,把网络设计为 ,即直接把恒等映射作为网络的一部分**。就可以把问题转化为**学习一个残差函数$ F(x)=H(x)−x$。
只要 ,就构成了一个恒等映射$ H(x)=x$。 而且,拟合残差至少比拟合恒等映射容易得多。于是,就有了 Residual block 结构。
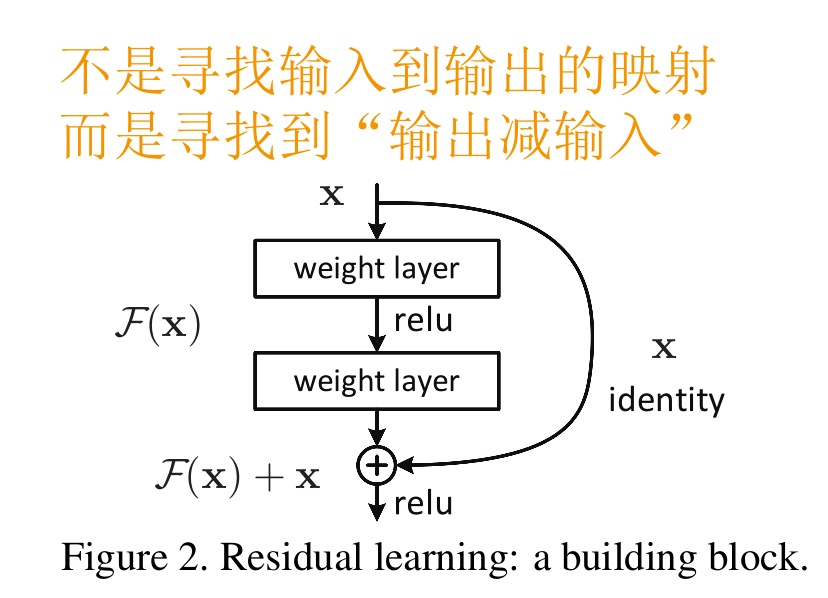
图中右侧的曲线叫做跳接(shortcut connection),通过跳接在激活函数前,将上一层(或几层)之前的输出与本层计算的输出相加,将求和的结果输入到激活函数中做为本层的输出。
用数学语言描述,假设 Residual Block 的输入为 ,则输出 等于:。 就是我们要学习的目标,即输出和输入的残差 。
Resnet结构
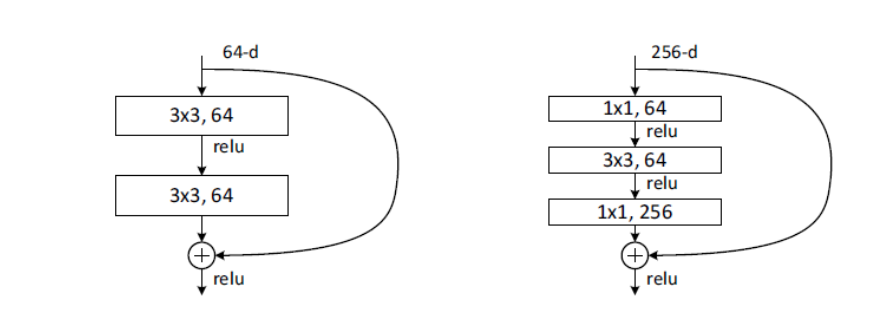
ResNet block有两种,一种两层结构,一种三层结构。
咱们要求解的映射为:H(x)
现在咱们将这个问题转换为求解网络的残差映射函数,也就是F(x),其中F(x) = H(x)-x。残差:观测值与估计值之间的差。
这里H(x)就是观测值,x就是估计值(也就是上一层ResNet输出的特征映射)。
我们一般称x为identity Function,它是一个跳跃连接;称F(x)为ResNet Function。那么咱们要求解的问题变成了H(x) = F(x)+x。
上图左中的残差块的实现如下,可以设定输出通道数,是否使用1*1的卷积及卷积层的步幅。
# 导入相关的工具包
import tensorflow as tf
from tensorflow.keras import layers, activations
# 定义ResNet的残差块
class Residual(tf.keras.Model):
# 指明残差块的通道数,是否使用1*1卷积,步长
def __init__(self, num_channels, use_1x1conv=False, strides=1):
super(Residual, self).__init__()
# 卷积层:指明卷积核个数,padding,卷积核大小,步长
self.conv1 = layers.Conv2D(num_channels,
padding='same',
kernel_size=3,
strides=strides)
# 卷积层:指明卷积核个数,padding,卷积核大小,步长
self.conv2 = layers.Conv2D(num_channels, kernel_size=3, padding='same')
if use_1x1conv:
self.conv3 = layers.Conv2D(num_channels,
kernel_size=1,
strides=strides)
else:
self.conv3 = None
# 指明BN层
self.bn1 = layers.BatchNormalization()
self.bn2 = layers.BatchNormalization()
# 定义前向传播过程
def call(self, X):
# 卷积,BN,激活
Y = activations.relu(self.bn1(self.conv1(X)))
# 卷积,BN
Y = self.bn2(self.conv2(Y))
# 对输入数据进行1*1卷积保证通道数相同
if self.conv3:
X = self.conv3(X)
# 返回与输入相加后激活的结果
return activations.relu(Y + X)
Resnet经典网络结构
ResNet的经典网络结构有:ResNet-18、ResNet-34、ResNet-50、ResNet-101、ResNet-152几种,其中,ResNet-18和ResNet-34的基本结构相同,属于相对浅层的网络,后面3种的基本结构不同于ResNet-18和ResNet-34,属于更深层的网络。
不论是多少层的ResNet网络,它们都有以下共同点:
- 网络一共包含5个卷积组,每个卷积组中包含1个或多个基本的卷积计算过程(Conv-> BN->ReLU)
- 每个卷积组中包含1次下采样操作,使特征图大小减半,下采样通过以下两种方式实现:
- 最大池化,步长取2,只用于第2个卷积组(Conv2_x)
- 卷积,步长取2,用于除第2个卷积组之外的4个卷积组
- 第1个卷积组只包含1次卷积计算操作,5种典型ResNet结构的第1个卷积组完全相同,卷积核均为7x7, 步长为均2
- 第2-5个卷积组都包含多个相同的残差单元,在很多代码实现上,通常把第2-5个卷积组分别叫做Stage1、Stage2、Stage3、Stage4
Resnet-34
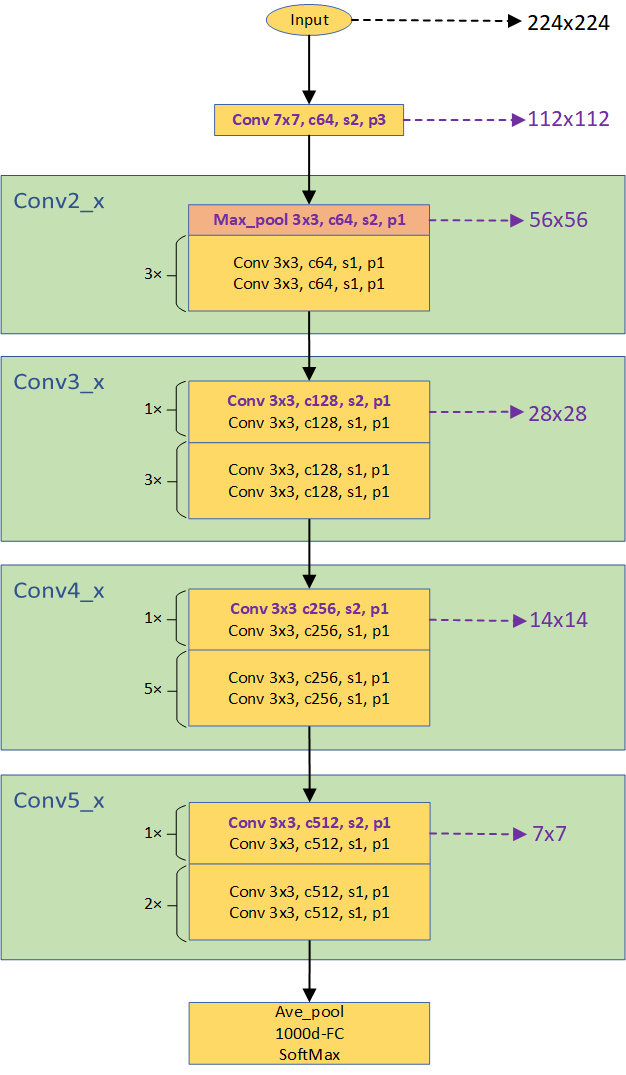
关于上图有几点需要解释:
- 每个绿色的矩形框表示ResNet的一个Stage,从上到下为Stage1 (Conv2_x)、Stage2 (Conv3_x)、Stage3 (Conv4_x)、Stage4 (Conv5_x)
- 绿色矩形框内的每个黄色的矩形框表示1个或多个标准的残差单元,黄色矩形框左侧的数值表示残差单元级联的数量,如5x表示5个级联的残差单元
- 通道数变化:输入通道为3,4个Stage的通道数依次为64、128、256、512,即每经过一个Stage通道数翻倍
- 层数计算:每个Stage包含的残差单元数量依次为3、4、6、3,每个残差单元包含2个卷积层,再算上第一个7x7卷积层和3x3最大池化层,总的层数=(3+4+6+3)*2+1+1 = 34
- 下采样:黄色矩形框中紫色的部分代表发生下采样操作,即特征图大小减半,右侧箭头标识即为下采样后的特征图大小(输入224x224为例);第一个绿色矩形框内的橙色矩形框表示最大池化,此处发生第一次下采样
- 卷积层参数解释:以Conv 3x3, c512, s2, p1为例, 3x3表示卷积核大小,c512表示卷积核数量/输出通道数量为512,s2表示卷积步长为2,p1表示卷积的padding取1。
- 池化层参数解释:Max_pool 3x3, c64, s2, p1,3x3表示池化的区域大小(类似于卷积核大小),c64表示输入输出通道为64,s2表示池化的步长为2,p1表示padding取1
对结构有一个大致的了解后,我们会发现:ResNet中的下采样操作发生在每个Stage的第一个残差单元或最大池化层,实现方式是操作都是通过在卷积或者池化中取步长为2。
另外,对于另外1个网络ResNet-18,和ResNet-34的区别在于每个Stage级联的残差单元数量不同,ResNet-18 4个Stage残差单元数量均为2,总层数=(2+2+2+2)*2+1+1 = 18
Resnet-50
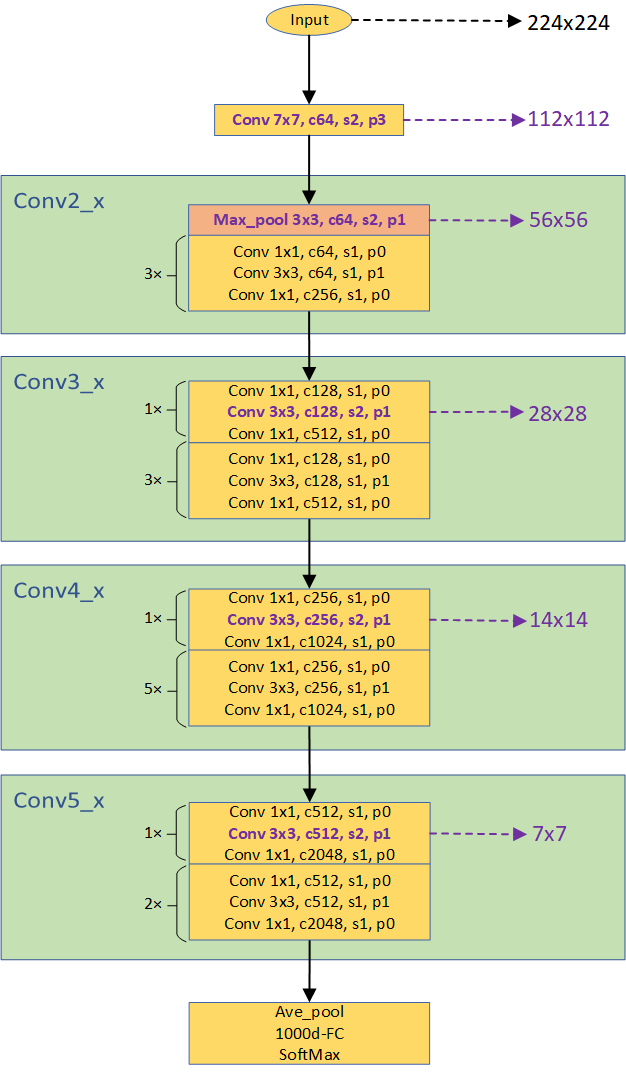
与ResNet-18/34的主要区别在于以下几点:
- 基本残差单元
- ResNet-18/34的残差单元包含2个3x3卷积层
- ResNet-50的残差单元包含3个卷积层,依次为1x1,3x3和1x1
- 通道数变化
- ResNet-18/34的通道数在每个Stage的第1个残差单元的第1个卷积层输出翻倍,后续通道数保持不变
- ResNet-50的通道数在每个Stage的第1个残差单元的输出部分翻倍,而每个残差单元内部也伴随着通道数的变化(有减少也有增加,依靠1x1卷积层来调节),这主要是为了在深层的网络中减少参数数量。
- 下采样时刻
- ResNet-18/34的下采样操作发生在每个Stage(不包括Stage1)第1个残差单元中的第1个卷积层(conv 3x3)
- ResNet-50的下采样操作发生在每个Stage(不包括Stage1)第1个残差单元中的第2个卷积层(conv 3x3)
类似的,对于ResNet-101/152,与ResNet-50的区别也仅在于与每个Stage残差单元数量的不同,ResNet-50为(3,4,6,3),ResNet-101为(3,4,23,3),ResNet-152为(3,8,36,3),总层数的计算方式与ResNet-34类似,只是残差单元中卷积层数量由变为3。
一些代码
resnet-18
import torch
import torch.nn as nn
from torch.nn import functional as F
class RestNetBasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(RestNetBasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
output = self.conv1(x)
output = F.relu(self.bn1(output))
output = self.conv2(output)
output = self.bn2(output)
return F.relu(x + output)
class RestNetDownBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(RestNetDownBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride[0], padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride[1], padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.extra = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], padding=0),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
extra_x = self.extra(x)
output = self.conv1(x)
out = F.relu(self.bn1(output))
out = self.conv2(out)
out = self.bn2(out)
return F.relu(extra_x + out)
class RestNet18(nn.Module):
def __init__(self):
super(RestNet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = nn.Sequential(RestNetBasicBlock(64, 64, 1),
RestNetBasicBlock(64, 64, 1))
self.layer2 = nn.Sequential(RestNetDownBlock(64, 128, [2, 1]),
RestNetBasicBlock(128, 128, 1))
self.layer3 = nn.Sequential(RestNetDownBlock(128, 256, [2, 1]),
RestNetBasicBlock(256, 256, 1))
self.layer4 = nn.Sequential(RestNetDownBlock(256, 512, [2, 1]),
RestNetBasicBlock(512, 512, 1))
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.fc = nn.Linear(512, 10)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = out.reshape(x.shape[0], -1)
out = self.fc(out)
return out